

MercuryAI vs. ChatGPT: What Inception Labs’ New Model Means for the Future of AI
AI language models are the engines behind everything from chatbots to content creation platforms. They help write, code, research, and translate—all by predicting the next word in a sentence. Models like OpenAI's ChatGPT have popularized this technology, setting a benchmark for conversational AI. But a new contender, MercuryAI, introduced by Inception Labs, is rewriting the rules.
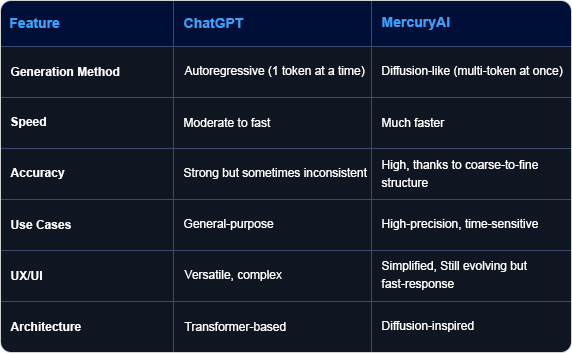
According to Inception Labs’ official announcement, MercuryAI introduces a radically different architecture that challenges the foundational approach of models like ChatGPT. Rather than following the standard autoregressive method—predicting one token at a time—MercuryAI uses a diffusion-based algorithm that generates multiple tokens in parallel.
Comparison with ChatGPT
ChatGPT, developed by OpenAI, relies on a transformer-based, autoregressive model. It generates text one token at a time in sequence, which allows for fine-grained control but comes with limitations in speed and context optimization. Despite powerful capabilities, it can struggle with latency under heavy loads and is prone to generating inaccurate or outdated information when not backed by live retrieval tools.

MercuryAI, in contrast, is built on a fundamentally new architecture inspired by diffusion models (similar to those used in image generation like DALL•E and Stable Diffusion). Instead of outputting one word or token at a time, MercuryAI can predict and generate multiple tokens simultaneously. This architectural leap gives it a massive speed advantage and makes it less prone to cumulative prediction errors.
Diffusion models provide a paradigm shift. These models operate with a coarse-to-fine generation process, where the output is refined from pure noise over a few "denoising" steps. This allows the model to shape its outputs more holistically from the start, leading to greater consistency and structural coherence.
Key Differentiators:
- Algorithm: MercuryAI uses a diffusion-inspired architecture for language generation; ChatGPT uses a transformer-based autoregressive model.
- Speed: MercuryAI generates many tokens at once, drastically improving response time.
- Accuracy: MercuryAI can maintain better global coherence since it plans more of the output in parallel.
- User Experience: MercuryAI offers ultra-low latency and high responsiveness in real-time applications.
MercuryAI’s architecture shift isn’t just an upgrade—it’s a signal that the underlying assumptions about how language models should work are evolving.
Future of AI Technology
MercuryAI could usher in a new era of non-autoregressive language models, where performance doesn’t mean compromising context or quality. As diffusion-like approaches are refined, we may see models that generate full paragraphs instantly, with better contextual planning and fewer factual errors.
Inception Labs is likely just getting started. As these new architectures prove scalable, other research labs may follow. OpenAI, DeepMind, Meta, and Anthropic are all exploring architectures beyond traditional transformers, including mixture-of-experts and planning-capable agents.
Expect major developments in:
- Parallel processing for text generation
- Multimodal integration (text + image + voice)
- Fine-tuned vertical models for specific industries
- Smarter planning agents that can reason and act over longer time frames
As these innovations mature, we may also see more accessible tools for businesses, developers, and content creators to harness these advances without needing deep technical knowledge.
Conclusion
The biggest story behind MercuryAI isn’t just that it’s faster than ChatGPT—it’s that it uses a fundamentally different approach to language generation. By embracing diffusion-like algorithms that output multiple tokens in parallel, Inception Labs has taken a bold step toward reshaping how language models are built.
As AI continues evolving, this shift in architecture could lead to models that are not only faster but smarter, more reliable, and more aligned with human needs. MercuryAI represents more than a new tool—it represents a new generation of AI thinking.
Other innovations like Microsoft’s 1-bit LLM and techniques like using a smaller draft model will help reduce computational costs, accelerate inference, and make powerful AI more accessible across devices and industries.
Frequently Asked Questions (FAQs)
Final Thoughts
MercuryAI may be the next step toward faster, more precise AI—but it's also a sign of where the entire field is headed. Whether it's Inception Labs, OpenAI, or another innovator, the shift is clear: smarter tools, tuned for real-world impact.
At Kaira Software, we keep a close eye on these advancements to help our clients stay ahead. From integrating AI in enterprise apps to building custom solutions with cutting-edge models, we’re ready for what’s next.
Want to explore AI solutions for your business? Get in touch with us and let’s build something future-ready.